
JUstory
[추천시스템] Context-aware Recommendation 본문
Context - aware Recommender System
: 유저와 아이템 간 상호작용 정보 뿐만 아니라, 맥락 (context)적 정보도 함께 반영하는 추천시스템
X를 통해 Y의 값을 추론하는 일반적인 예측 문제에 두루 사용 가능 -> General Predictor

Content-based; item이나 user와 관련된 feature
Content-aware; Time, Location, Social information 등
Click - Through Rate Prediction
CTR 예측 : 유저가 주어진 아이템을 클릭할 확률을 예측하는 문제
- 예측해야 하는 y값은 클릭 여부, 즉 0 또는 1이므로 이진 분류(binary classification)문제에 해당
- 모델에서 출력한 실수 값을 시그모이드(sigmoid)함수에 통과시키면 (0,1) 사이의 예측 CTR 값이 됨
CTR 예측은 광고에 주로 사용됨
- 광고 추천을 잘하면 곧 돈이 됨. 그래서 매우 중요
- 광고가 노출된 상황의 다양한 유저, 광고, 컨텍스트 피쳐를 모델의 입력 변수로 사용
- 유저 ID가 존재하지 않는 데이터도 다른 유저 피쳐나 컨텍스트 피쳐를 사용하여 예측할 수 있음
Dense Feature vs. Sparse Feature
dense feature: 벡터로 표현했을 시 비교적 작은 공간에 밀집되어 분포하는 수치형 변수 ex. 유저-아이템 평점, 기온, 시간
sparse feature: 벡터로 표현했을 시 비교적 넓은 공간에 분포하는 범주형 변수 ex. 유저/아이템 ID, 요일, 분류, 키워드
CTR 예측 문제에 사용되는 데이터를 구성하는 요소는 대부분 sparse feature임
Feature Embedding
One- hot Encoding의 한계
- 파라미터 수가 너무 많아질 수 있음
- 학습 데이터에 등장하는 빈도에 따라 특정 카테고리가 과적합/ 과소적합 될 수 있음
따라서 피쳐 임베딩을 한 이후에 이 피쳐를 가지고 예측을 하기도 함
Item2Vec : 아이템을 벡터로 나타내는 것
자연어 처리에 사용되는 텍스트 임베딩 기법들이 흔히 적용됨
- Latent Dirichlet Allocation(Topic Modeling)
- BERT (Pretrained Laguage Model)
컨텍스트 기반 추천 알고리즘의 변천사
(~90s) 로지스틱 회귀 / 서포트 벡터 머신
(1999) Matrix Factorization의 출현
(2008) "Context-aware Recommendation"이라는 개념 출현
(2010) Factorization Machine의 출현
(2016) Field-aware Factorization Machine의 출현
Factorization Machine (FM)
등장 배경
딥러닝이 등장하기 이전에는 SVM이 가장 많이 사용되는 모델이었음
그럼에도 CF 환경에서는 SVM보다 MF 계열의 모델이 더 높은 성능을 내왔음
하지만 MF 모델은 특별한 환경 혹은 데이터에만 적용할 수 있음. -> SVM + MF 의 장점 결합하고자 함
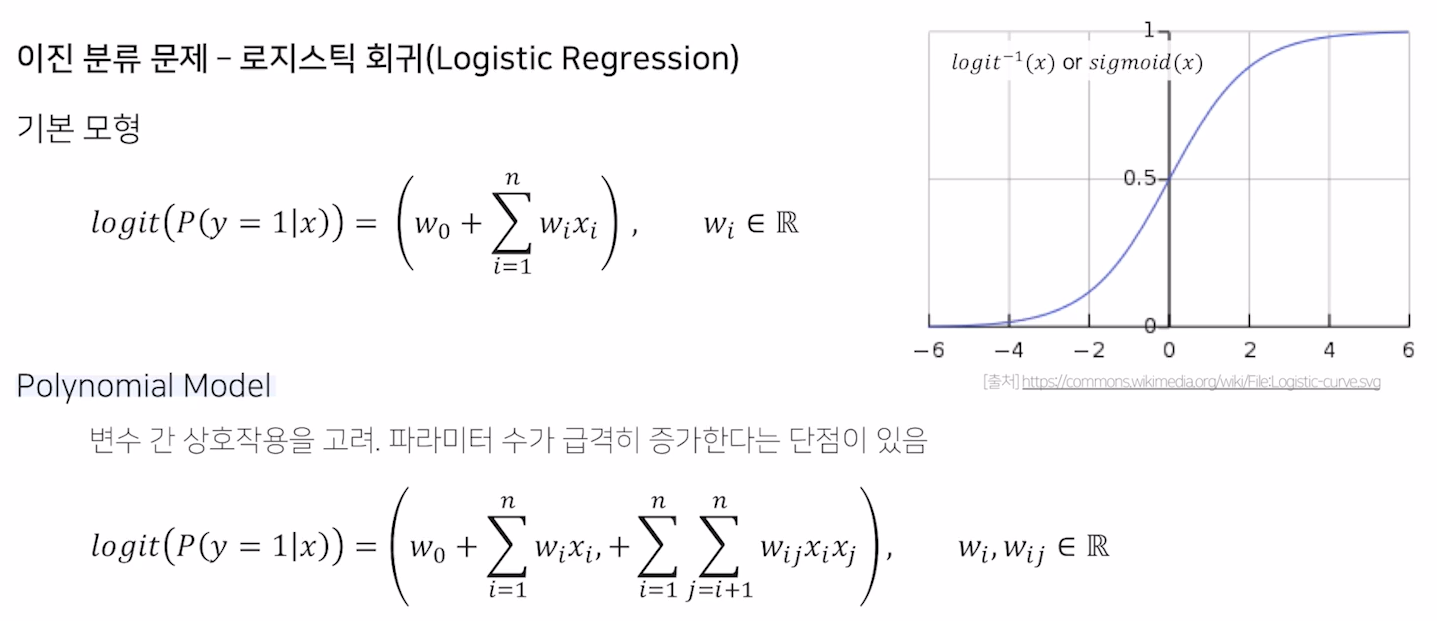
FM 공식
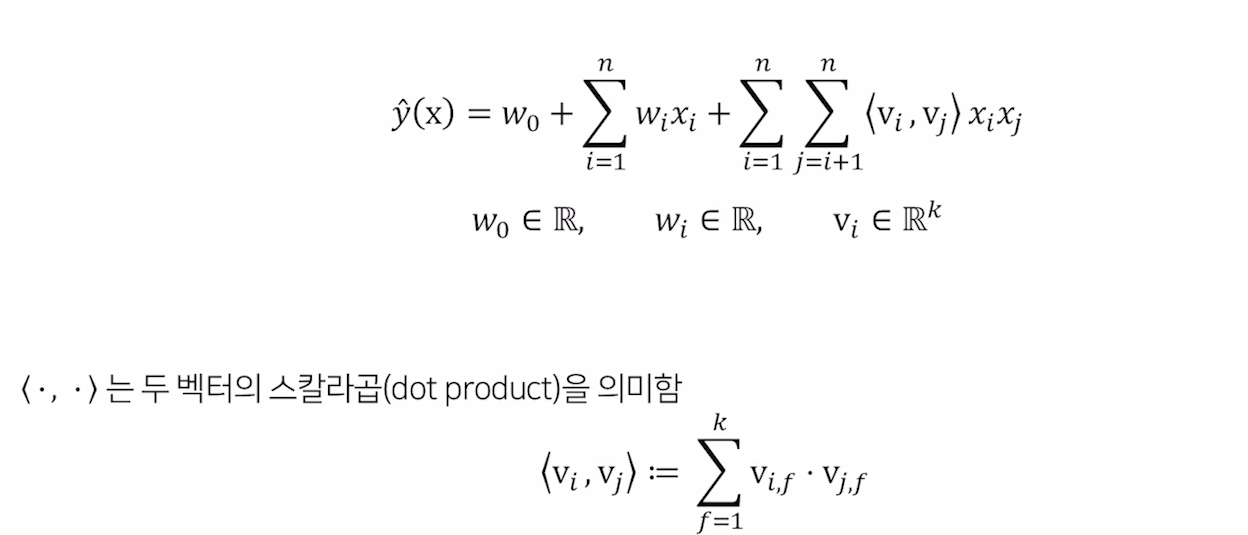

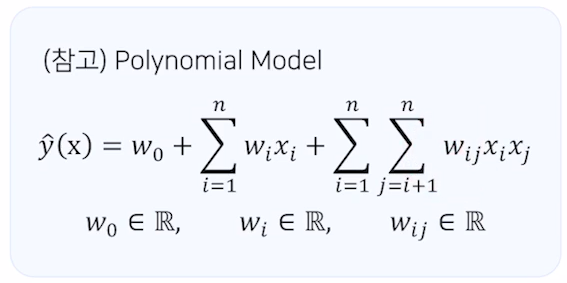
FM 은 xi 와 xj의 상호작용을 각각 vi와 vj라는 k차원의 factorization parameter로 표현
활용
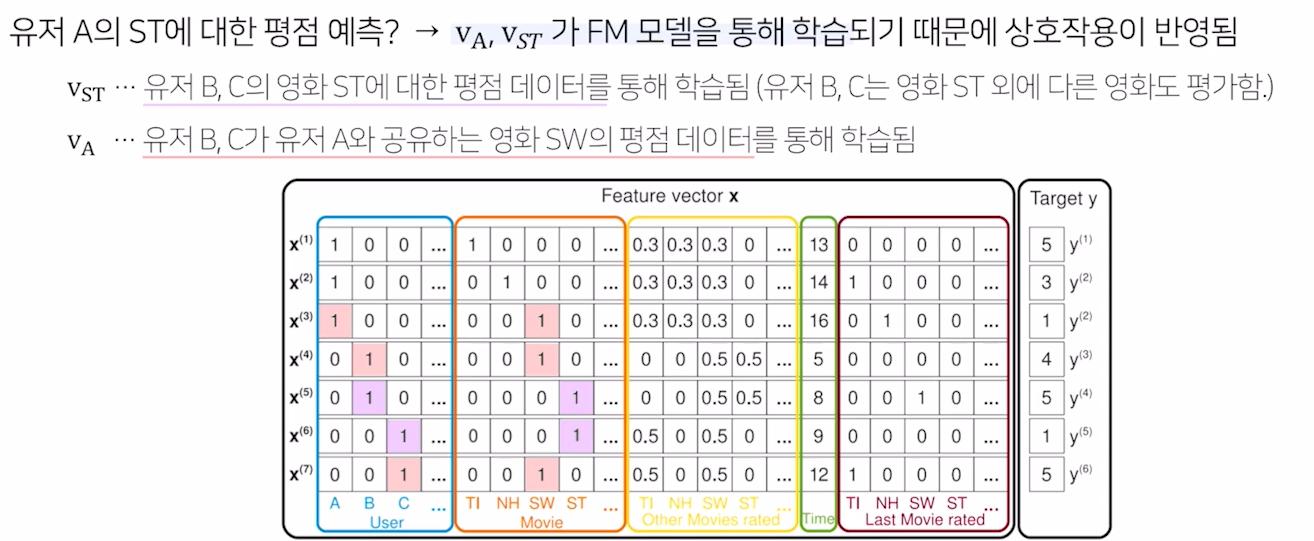
# Sparse한 데이터셋에서 예측하기
유저의 영화에 대한 평점 데이터는 대표적인 High Sparsity 데이터
평점 데이터 = {(유저1, 영화2, 5), (유저3, 영화1, 4), (유저2, 영화3, 1), ...}
위의 평점 데이터를 일반적인 입력 데이터로 바꾸면, 입력 값의 차원이 전체 유저와 아이템 수만큼 증가
ex. 유저 U명, 영화 M개
(유저1, 영화2, 5) -> [1,0,0, ... , 0, 0,1,0,0,0, ... , 0, 5]
(유저3, 영화1, 4) -> [0,0,1, ... , 0, 1,0,0,0,0, ... , 0, 4]
장점
vs. SVM
- 매우 sparse한 데이터에 대해서 높은 성능을 보임
- 선형 복잡도를 가지므로 수십 억 개의 학습 데이터에 대해서도 빠르게 학습함/ 모델의 학습에 필요한 파라미터의 개수도 선형적으로 비례
vs. Matrix Factorization
- 여러 예측 문제 (회귀/ 분류/ 랭킹)에 모두 활용 가능한 범용적인 지도 학습 모델
- 일반적인 실수 변수를 모델의 입력으로 사용함/ MF와 비교했을 때 유저, 아이템 ID 외에 다른 부가 정보들을 모델의 피쳐로 사용할 수 있음
Field-aware Factorization Machines for CTR Prediction
등장 배경
FM은 예측 문제에 두루 적용 가능한 모델로, 특히 sparse 데이터로 구성된 CTR 예측에서 좋은 성능을 보임
Field- aware Factorization Machine(FFM)은 FM을 발전시킨 모델로서 PITF 모델에서 아이디어를 얻음
PITF: Pairwise Interaction Tensor Factorization
PITF에서는 (user, item, tag) 3개의 필드에 대한 클릭률을 예측하기 위해
(user, item), (item, tag), (user, tag) 각각에 대해서 서로 다른 latent factor를 정의하여 구함
--> 이를 일반화하여 여러 개의 필드에 대해서 latent factor를 정의하는 것이 FFM
특징
입력 변수를 필드 (field)로 나누어, 필드별로 서로 다른 latent factor를 가지도록 factorize함.
- 기존의 FM은 하나의 변수에 대해서 k개로 factorize했으나 FFM은 f개의 필드에 대해 각각 k개로 factorize함
Field는 모델을 설계할 때 함께 정의되며, 같은 의미를 갖는 변수들의 집합으로 설정함
유저; 성별, 디바이스, 운영체제 / 아이템; 광고, 카테고리 / 컨텍스트; 어플리케이션, 배너
--> CTR 예측에 사용되는 피쳐는 이보다 훨씬 다양한데, 피쳐의 개수만큼 필드를 정의하여 사용할 수 있음
FFM 공식


필드 구성


성능 비교
데이터 셋에 따라 조금씩 다르지만 LR에 비해 FM, FFM이 더 좋은 성능을 보임

Gradient Boosting Machine (GBM)
Gradient Boosting Machine(GBM)을 통한 CTR 예측
CTR 예측을 통해 개인화된 추천 시스템을 만들 수 있는 또 다른 대표적인 모델
Boosting
앙상블 기법의 일종
: 모델의 편향에 따른 예측 오차를 줄이기 위해 여러 모델을 결합하여 사용하는 기법
의사결정 나무로 된 weak learner들을 연속적으로 학습하여 결합하는 방식
: 이전 단계의 weak learner가 취약했던 부분을 위주로 데이터를 샘플링하거나 가중치를 부여해 다음 단계의 learner를 학습한다는 의미
Gradient Boosting
gradient descent를 사용하여 loss function이 줄어드는 방향 (negative gradient)으로 week learner들을 반복적으로 결합함으로써 성능을 향상시키는 Boosting 알고리즘
Gradient Boosting as Residual Fitting
통계학적 관점에서, Graient Boosting은 잔차를 적합하는 것으로 이해할 수 있음
이전 단계의 weak learner까지의 residual을 계산하여, 이를 예측하는 다음 weak learner을 학습함

회귀 문제에서는 예측값으로 residual을 그대로 사용하고, 분류 문제에서는 log(odds)값을 사용함
장점
대체로 random forest보다 나은 성능을 보임
단점
- 느린 학습 속도 - 과적합 문제
Textual Content
Collaborative Deep Learning (CDL) 모델
: textual content를 활용한 Top-K Ranking 추천 모델
CDL = MF + Stacked Denoising Autoencoder (SDAE)


Stacked Denoising Autoencoders (SDAE)

Textual Content
CDL과 유사하게 textual content (주로 아이템의 review data)를 side-information으로 활용한 연구들이 여럿 있음.


Visual Content
Visual BPR

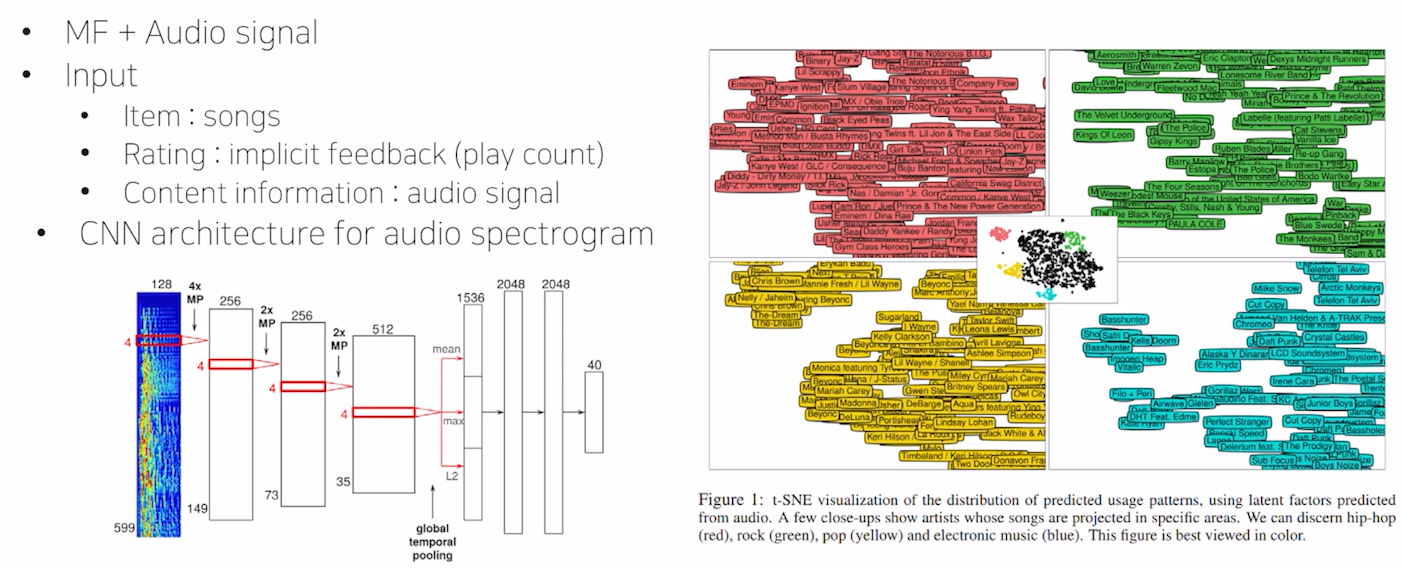
Audio Content
Deep content-based music recommendation
Social Networks and Groups
Socially-aware recommendations
: 사용자의 social networks 정보를 content로서 활용함으로써 cold-start problem을 완화하고 interpretability를 높일 수 있음
Idea: 'social trust: the fact that a friend has liked or purchased an item is a strong predictor of a user's future behavior'
How: Rating 행렬 R와 사용자 인접 행렬 A를 사용자라는 공통의 요소로 묶어서 목적함수를 설계함


Group-aware recommenations
: 사용자 그룹에게 집단적으로 추천이 이루어지는 시나리오. 사용자 개개인 뿐만 아니라 사용자가 속한 그룹과의 관련성을 함께 고려해야함
Idea : 그룹을 고려한 추천을 위해서 1) 추천되는 아이템이 사용자가 속한 그룹의 관심사와 관련이 있으며, 2) 그룹 내의 사용자들 간의 선호도가 크게 다르지 않아야 함.
How: 그룹과 아이템의 compatibility 및 그룹 내의 선호도의 일관성을 나타내는 함수를 정의함

'딥러닝' 카테고리의 다른 글
| [최적화/경량화] Pruning (1) | 2025.01.02 |
|---|---|
| [추천시스템] DeepCTR (7) | 2024.11.14 |
| [추천시스템] Recommender System with GNN / RNN (3) | 2024.11.13 |
| [추천시스템] Recommender System with DL / MLP / AE (4) | 2024.11.04 |
| [추천시스템] Item2Vec / ANN (0) | 2024.11.04 |



