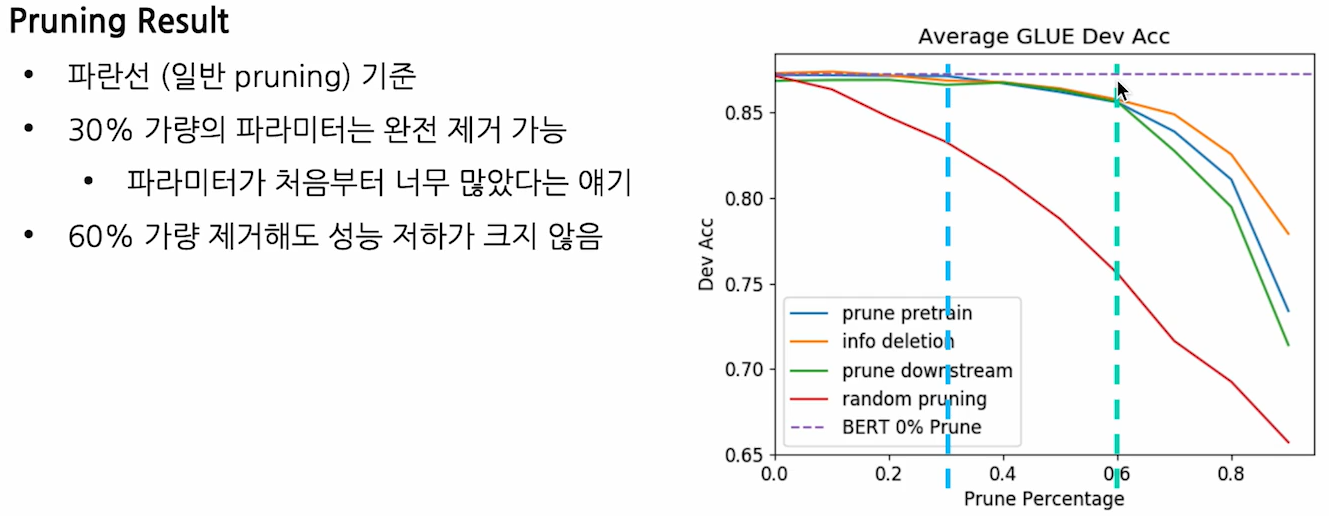
[최적화/경량화] Pruning
Pruning
: 신경망 모델에서, 노드(뉴런)나 연결(시냅스)을 제거하여 모델의 크기와 계산 비용을 줄이는 기법

- 메모리 사용을 줄이고 연산 속도를 가속하기 위함이 목표
- 성능은 최대한 유지하면서도 경량화를 최대한 할 수 있는 기법이 좋은 기법

Pruning 단위의 granularity에 따른 구분

| 방법 | 개념 | 단위 | 구조 변경 | 장점 | 단점 |
| Unstructured | 파라미터 하나하나 단위로, 값을 0으로 변경 | 개별 파라미터 단위 | 없음 | 구현이 쉬움 | 가속 실현이 어려움 (하드웨어 도움 필요) |
| Structured | 레어이 단위나 채널 단위처럼, 특정 구조 단위로 통째로 제거 | 특정 구조 단위 | 있음 | 가속 실현이 쉬움 (즉시 가속) |
구현이 어려움 (불가능한 경우도 ) |
Scoring
Pruning할 파라미터를 선정하는 방법에 따른 구분
덜 중요한 파라미터/ 레이어가 pruning의 대상
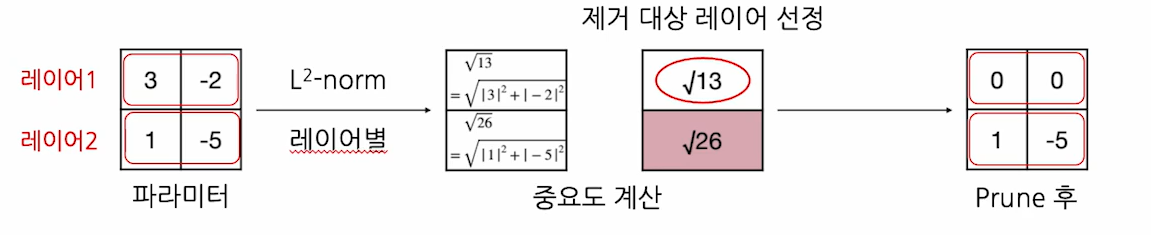
중요도를 계산하는 방법 : 파라미터/ 레이어 크기
1. 파라미터별로 절댓값을 중요도로 사용
- 절댒값이 작은 순으로 pruning 대상으로 선정

2. 레이어별로 L-norm을 중요도로 사용
- L2-norm이 작은 순으로 pruning 대상을 선정
계산된 중요도를 반영할 단위
1. Global Pruning
- 모델 전체에서 pruning
- 중요도를 전체에서 절대 비교
2. Local Pruning
- 특정 단위별로 각각을 pruning
- 중요도를 단위 내에서만 상대 비교


| 방법 | 단위 | 장점 | 단점 |
| Global | 전체 모델 단위 | 중요한 레이어가 보존됨 | 계산량이 많음 (전체에서 비교) |
| Local | 계층 단위 | 특정 레이어에 pruning이 편중되지 않음 | 중요한 레이어가 과도하게 pruning될 수 있음 |
Scheduling
Pruning 및 fine-tuning을 언제, 얼마나 할 것인지에 따른 구분
1. One-shot (single iteration)
- Pruning을 한번만 진행
2. Recursive (multiple iterations)
- Pruning은 한번에 많이 하면 성능 손실이 클 수도 있음
- Pruning을 조금씩 여러번에 나눠서 진행
| 방법 | 장점 | 단점 |
| One-shot (single iteration) |
시간이 절약됨 | 성능이 불안정 |
| Recursive (multiple iterations) |
안정적인 성능 | 시간이 오래 걸 |
Initialization
Fine-tuning 시, 파라미터 초기화를 하는 방법에 따른 구분
Pruning 직후엔 학습된 모델 파라미터 중 일부만 잘려나간 상태
이후 최종 모델까지 추가 학습을 어떤 상태 (파라미터 값)로 시작할지에 대한 구분
1. Weight-preserving (classic)
- Pruning 직후 상태로 그대로 이어서 fine-tuning 진행

2. Weight-reinitializing (rewinding)
- 랜덤 값으로 재초기화 후 재학습 진행

| 방법 | 설명 | 장점 | 단점 |
| Weight-preserving (classic) |
Pruning 후 이어서 fine-tune | 학습/수렴이 빠름 | 성능이 불안정함 |
| Weight-reinitializing (rewinding) |
파라미터를 랜덤으로 초기화 | 성능이 안정적으로 좋음 | 재학습이 필요 |
가장 기본적인 pruning 방법 : Iterative Magnitude Pruning (IMP)
Structured; Unstructured pruning
Scoring; 절댓값을 중요도로 측정 & Global Pruning
Scheduling; Recursive 방식 활용
Initialization; Rewind 방식 활용
Matrix Sparsity
희소행렬 : 행렬의 대부분의 요소가 0인 행렬
Sparsity = 전체 중 0의 비율 (density = 1-sparsity)
Unstructured pruning은 파라미터 값을 0으로 바꾸는 방식
이 방식으로는 곧바로 계산 속도가 빨라지지 않음
이유; 여전히 0을 저장하고 있고. 여전히 0을 곱하고 있기 때문
해결책
1. Sparsity 가 심할때 : Sparse Matrix Representation
- 행렬에서 0이 아닌 값들의 좌표를 기억
- 메모리 및 연산 효율을 높일 수 있음


2. Sparsity 가 적당할때 : 전용 하드웨어 사용
- 곱셈 수행 전, 스캔을 통해 0의 위치를 파악 (overhead 약간 발생)
- 해당 위치를 건너뛰고 계산되도록 조정
Sensitivity Analysis
Pruning Ratio
: 파라미터의 몇 %를 제거할 것인지 비율
- Local : 레이어별로 동일하게 일정 비율을 제거
- 동일한 비율이라서 Uniform Shrink라고도 함
더 좋은 방법 : 레이어별로 비율을 다르게 설정하기!!
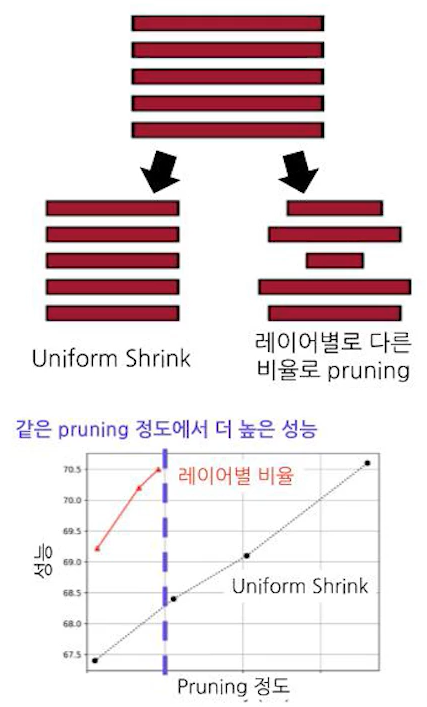
네트워크가 복잡하거나 / 층별 특성이 상이한 모델의 경우 사용

각 레이어의 특성을 반영
- 민감도가 높은 부분은 덜 Pruning
- 민감도가 낮은 부분은 더 Pruning
각 레이어의 Pruning 비율을 설정하는 중요도를 측정하는 개념의 방법 (Global pruning의 일종)
- 실험을 통해 측정하는 empirical, practical한 방법
Sensitivity (민감도)를 측정
- 파라미터/ 레이어의 민감도 : 해당 파라미터/ 레이어를 pruning했을때의 성능 저하 정도 측정
- 가장 앞 부분 레이어가 민감 ex. 인식/ 감각기관에 해당
- 뒷 부분 레이어는 덜 민감


레이어 별로, 비율 별로 각각 측정
측정 한번에 pruning 전체 과정 1번 만큼의 iteration이 소요됨
- 오래 걸리는 작업이기 때문에 주로 분석용으로 사용
- 단, 모델 구조가 같고 데이터만 다른 경우, 한번 계산해둔 비율은 재사용이 어느정도 가능
Pruning in CNNs
CNN (Convolutional Neural Network) - 이미지 데이터 처리에 적합한 딥러닝 모델 구조
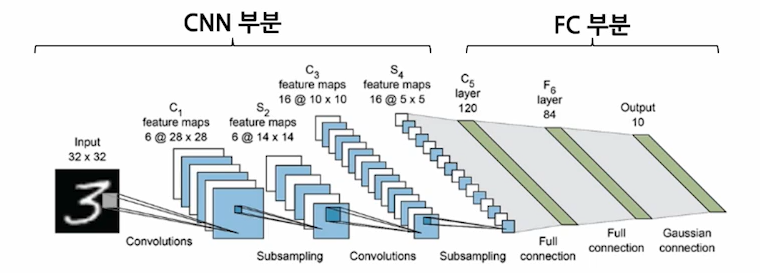
보통 CNN 모델은 CNN 부분과 FC 부분으로 나눠짐
대부분의 파라미터는 FC 부분에 있음. 그러나 연산속도의 bottleneck은 CNN 부분에 있음
따라서 공간/시간 효율을 모두 챙기려면 각각 pruning이 필요!
CNN Filters
CNN은 이미지에 적용할 적절한 filter를 학습함
filter란,
코 모양, 입 모양, 얼굴 윤곽 같은 이미지의 단위
이 filter가 이미지의 어느 위치에 있는지를 찾고
그 정보들을 조합하여 이미지를 분류할 수 있게 됨
좋은 filter들을 학습해 내는 것이 CNN의 목표
실제의 filter 한장은 행렬 한개
레이어 별로 각각 여러개의 filter가 있음
보통 앞쪽 레이어는 디테일을, 뒤쪽 레이어는 전체적을 구조를 파악하는 경향이 있음
Filter Pruning
이 중 중요도가 작은 filter를 제거하는 것이 CNN의 pruning
- Structured한 방법, 속도를 그 즉시 향상시킴 (Unstructured는 sparse convolution 연산 구현이 필요)
- sparse한 filter를 우선적으로 제거 (sparsity 높은 순으로)
한 레이어에 있는 filter들의 실제 모습
- 절반 정도는 sparse하거나 거의 0에 가까운 값들로 이뤄짐

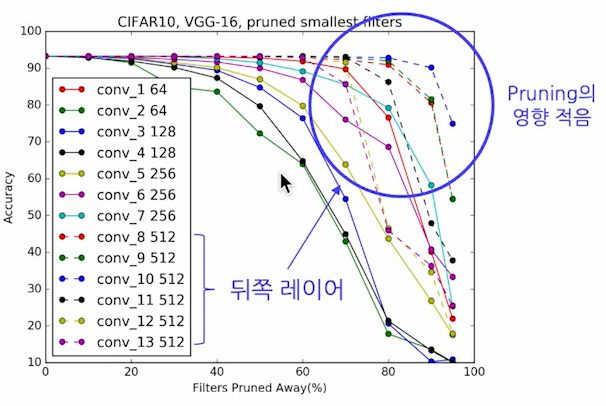
spase한 filter를 제거하는 것이 정말 좋은 기준일까? - sensitivity analysis
- spase한 filter의 비율이 높은 레이어는 pruning을 많이 해도 성능 저하가 덜함

sensitivity analysis에 따르면 뒤쪽 레이어가 덜 민감함
- 일부 레이어는 90% 씩 삭제해도 문제 없음. 큰 형태는 다양성이 비교적 적기 때문
- 반면, 앞쪽 레이어는 너무 많이 제거하면 모델이 이미지를 파악할 수 없음. 다양성이 크기 때문
따라서 CNN은 pruning할 때 전체 제거 비율을 레이어별로 나눠서 분배해야함
Pruning in BERT
BERT (Bidirectional Encoder Representations from Transformer)
LLM 시대 직전에 있었던 다용도 언어 모델
단어 자동 완성, 문장 분류, 문장 관계 파악 등이 가능한 모델


Layers of BERT
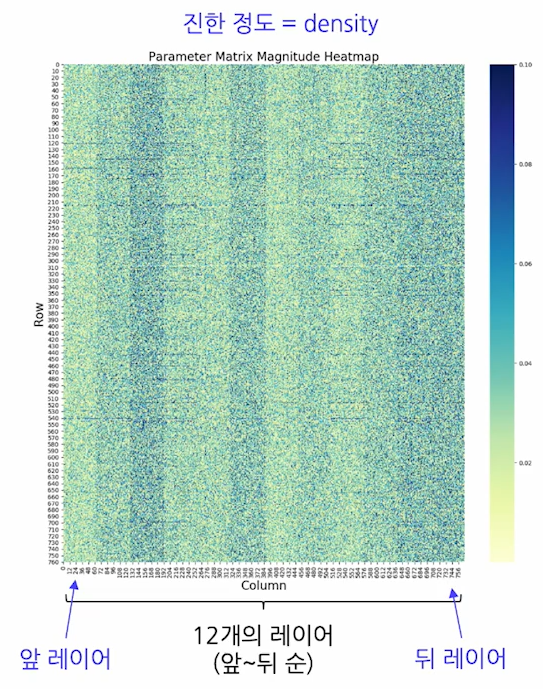
언어 모델도 보통 앞 레이어는 작은 형태 (단어 등), 뒤쪽 레이어는 큰 형태 (문장 등)
그러나 레이어별 sparsity가 비일관적
- sparsity가 낮아졌다 높아졌다 하는 특이 패턴
- 따라서 Global Pruning은 부적합
- Structured Pruning도 위험. 레이어별 역할이 명확할 것으로 예상
그러나 여전히 대부분의 파라미터가 0에 가까움
- 따라서 절댓값 기준 pruning이 유효
First Layer

단어 모음인 vocabulary
- 벡터의 모음 = 행렬
- 실제로는 이 vocabulary가 첫번째 레이어를 담당. 정확히는 이에 대응하는 embedding matrix
특징 : 짧은 단어일수록 벡터가 더 sparse
- Local Pruning을 하면 짧은 단어 위주로 pruning을 하기 때문에 유효